Tasks
3MEthTaskforce provides baseline performance results for each of the three core tasks using several machine learning models. Here's a summary of the baseline performance.
User Behavior Prediction
Task Definition: Predict which users will buy or sell tokens and which tokens they are likely to transact with at a future time.
Baseline Models: Six dynamic Graph Neural Networks (GNNs) were evaluated for this task: DyGFormer, JODIE, DyRep, TGAT, TGN, and TCL.
Performance Metrics: The task was evaluated using two metrics: Test Set Average Precision (TAP) and New Node Average Precision (NAP).
Results:
- JODIE performed best, achieving a TAP of 0.955 and NAP of 0.920 when incorporating sentiment data from large language models (LLMs).
- DyGFormer also performed well, reaching TAP of 0.939 and NAP of 0.905 using global market indices and sentiment scores.
- TCL showed weaker performance, especially on sentiment-based models, with a TAP of 0.750 on the combined features (token data, global market, sentiment).
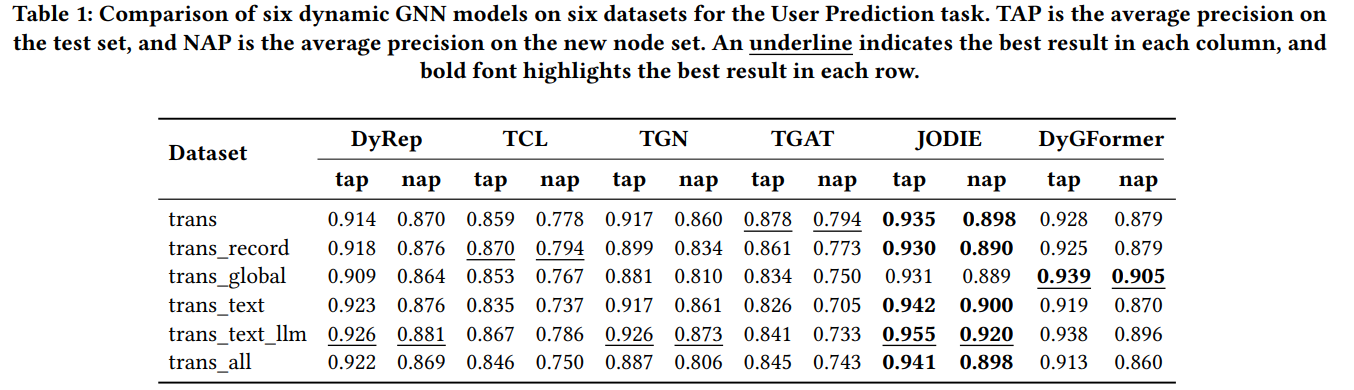
Key Insight: Incorporating sentiment and global market features significantly improved prediction accuracy across the models, particularly for JODIE and DyGFormer.
Token Price Prediction
Task Definition: Forecast the future price of tokens using historical price data, global market indices, and sentiment analysis.
Baseline Models: Two recurrent models, Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), were used for evaluation.
Performance Metric: The models were evaluated using Mean Squared Error (MSE).
Results:
- LSTM consistently outperformed GRU, particularly when incorporating additional features like sentiment and global indices.
- The best LSTM model achieved an MSE of 1.667 when using a combination of price, global market data, and sentiment, compared to an MSE of 2.271 for GRU.
- For newly issued tokens (with limited historical data), incorporating sentiment reduced the error further. For instance, MSE dropped from 0.532 to 0.511 when sentiment features were added.
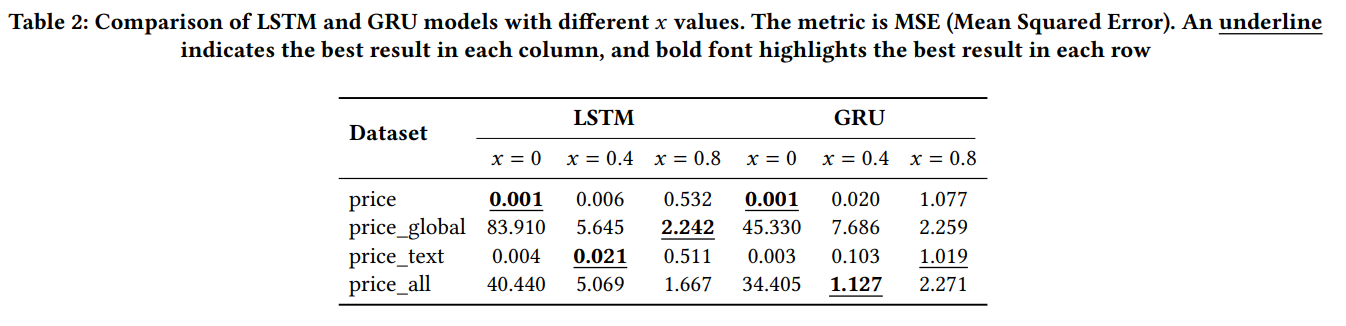
Key Insight: LSTM was more effective at price prediction, especially when using multimodal inputs (price, sentiment, market indices).
User Behavior Marking
Task Definition: Assign a risk score to a user's trading behavior by analyzing price fluctuations of tokens they buy and sell.
Methodology: The risk score is calculated based on traditional financial models, using the Capital Asset Pricing Model (CAPM) and variance in token prices during the user’s investment period.
Results:
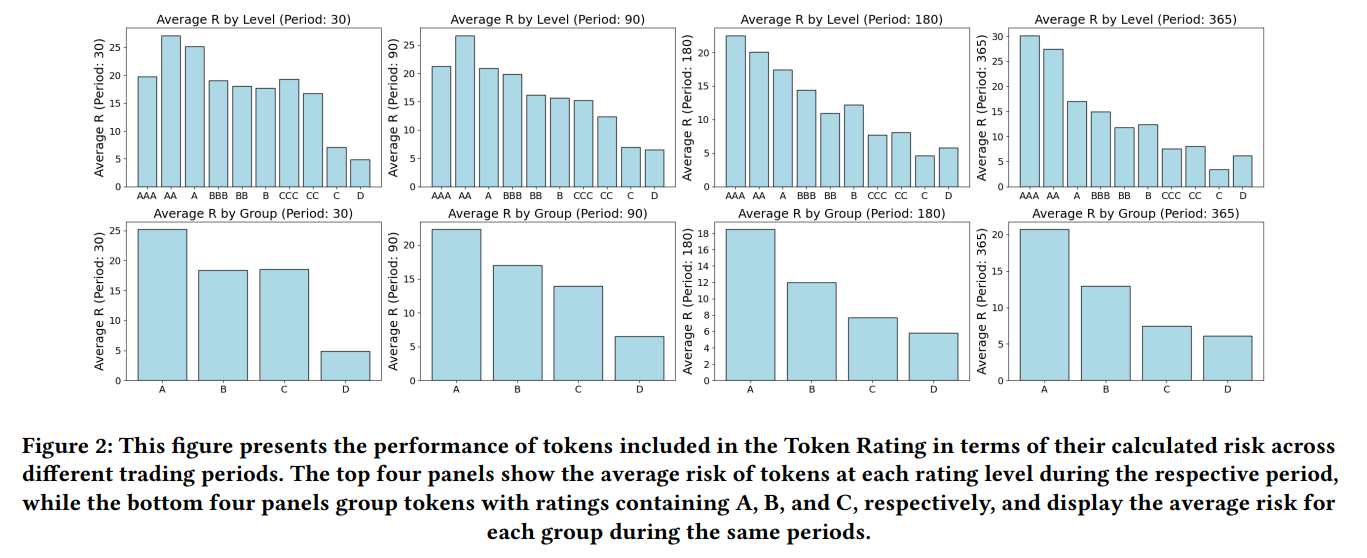
- TokenInsight Rating Evaluation: Tokens with higher ratings (e.g., AAA) showed lower average risk scores, while those with lower ratings (e.g., CCC or D) had higher risk scores.
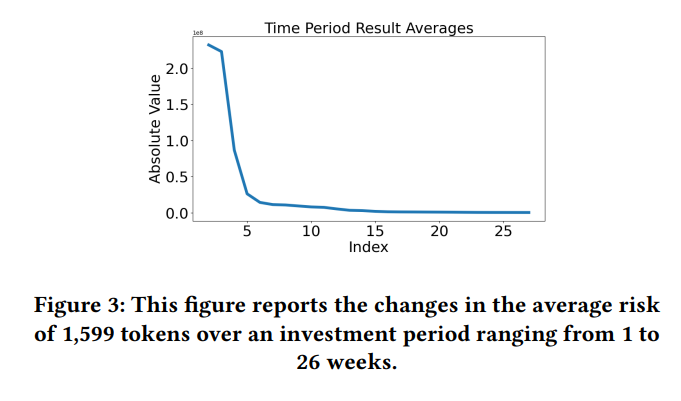
- Time Period Evaluation: Longer investment periods generally resulted in lower risk, validating that short-term trading carried higher risks.
- During the LUNA crash event, the average risk score increased dramatically (from 21.35 million before the incident to 24.66 million during the crash), indicating heightened market volatility and risk.